RLE Binary compression
Redstoner → Building → RLE Binary compression

#So here I am once again with an astounding build. This time though, it is a world’s first. #A Google search for “Minecraft binary compression” turns up piss all, so not only has this never been built before, it hasn’t even been discussed before.
So a quick run down of RLE compression. Basically, it looks at a binary number, say “11111111110000000000” and goes whoa there boy. That’s a long number. And since we have 10 “1’s” in a row, why don’t we just say 10 “1’s” then 10 “0’s”. It does that and makes the new number “110101010”, where (1) is the starting bit, (1010) is binary for 10, so that means 10 “1"s, and (1010) again for 10, so it translates to 10 “0"s. It made our previous 20 bit number into a nice 9 bit number. Over 50% savings!
#So here we have it. The behemoth.

#Currently it only has 3 lines of outputs bussed to a usable location, and I can’t be arsed to bus all of those outputs. So if you put in a complex number, look for the outputs yourself.
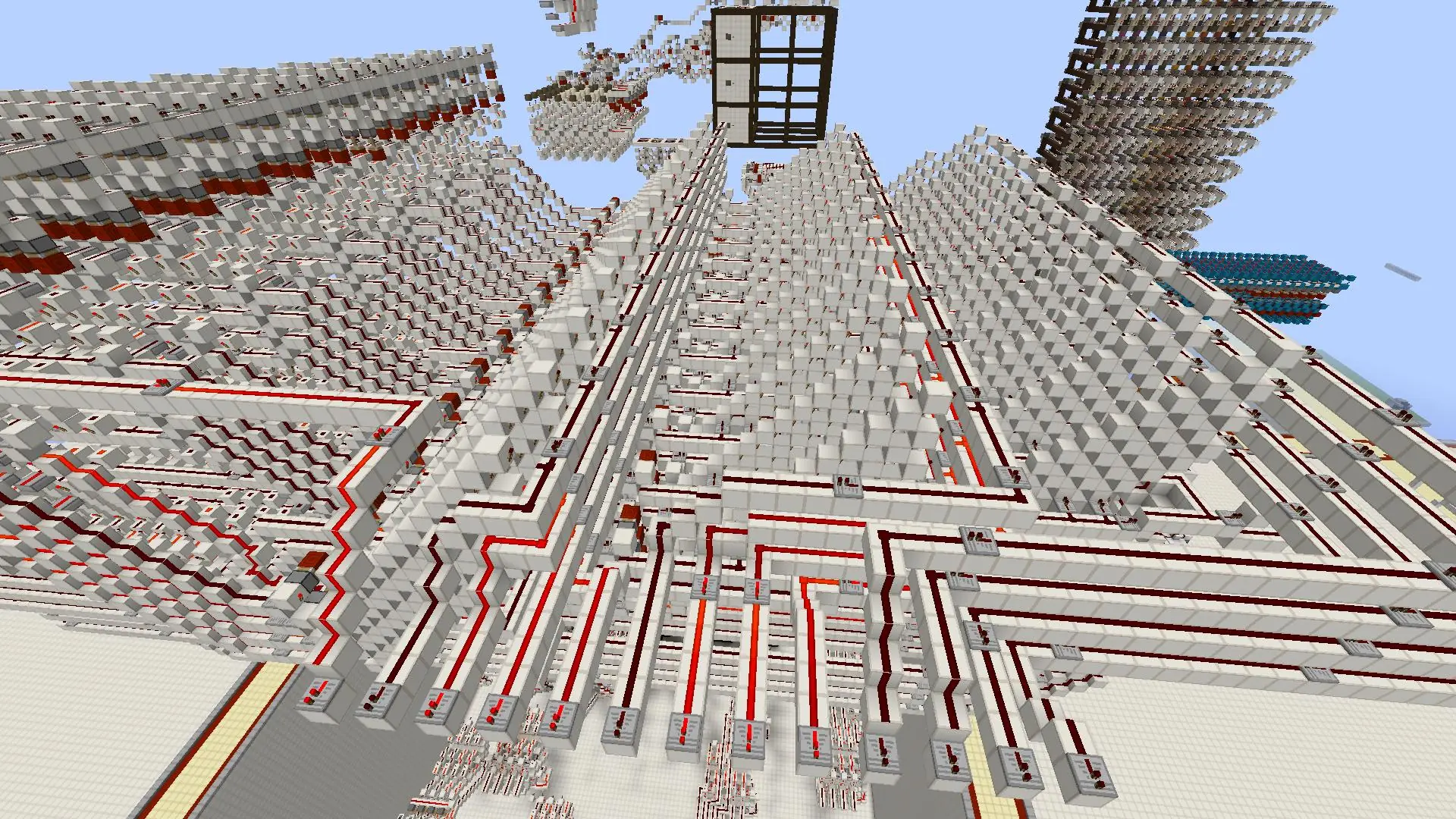
#Oh yea, that top layer isn’t even half of it.

#From another angle
#Bonus pixel art


Im… So comfused wtf is this EPIC BREH

Nice, that could be very useful for a GPU if you add a decoder to it.
I’ve only just looked at GZip and what I can see from my 5 minutes of research is that GZip creates codes for characters that have been repeated while the RLE system being demonstrated here has no regard for an input that is not binary. It seems that GZip only works with stuff translated into binary while RLE only works with the raw binary data. Mbey it would be possible to apply RLE compression after GZip to compress even more.
For instance, the word “woooow” in binary is 01110111 01101111 01101111 01101111 01101111 01110111. GZip would take the letters that are repeated and encode the two letters used to be 01110111(0) and 01101111(1) The new number would look like 01110111(0):01101111(1):1:1:1:0. I’ve used colons to separate letters and parentheses to represent the new code for the letter. Remove the colons and parentheses for the true solid binary number, but it is easier to read like that. So GZip looks for repeated letters specifically and encodes them. It has to be used with letters or other specified length encoding. RLE on the other hand only looks at the straight binary numbers. So the word “woooow” earlier would be combined into 01110111011011110110111101101111011011110111011 while running through the RLE converter, because it only looks for a single pattern, which is repeated digits. It gives no shits about larger patterns than that, and thus can be used with GZip, but wouldn’t work as well as it in this instance because of the GZip recognizing letters and RLE not giving a piss about them.
Also, I have just solved for the equation for RLE efficiency. If the output of: C = Number of bit changes (Like “111” has 0 bit changes but “0101” has 3) N = Length of number
((C+1)((Log2(N))+1)+1
is less than “N”, RLE compression will make your number smaller. If it is larger, stay away from RLE.

@LogalCoder
cough Ternary Computers cough
I know that this post is super old, but I have to correct myself earlier in the thread. The correct equation for determining if RLE is good is:
C = Number of bit changes (Like “111” has 0 bit changes but “0101” has 3) N = Length of number
((C+1)(((N-(2^{log{N}-{mod{log2{N},1}}}+1 -2^log{N}-{mod{log2{N},1}} )/2^{log{N}-{mod{log2{N},1}}}+1 -2^log{N}-{mod{log2{N},1}} ) +2^log{N}-{mod{log2{N},1}})+1)+1
So I realize that the new equation is kind of insane, but I wanted to share so that my previous work is correct.

WOW its crazy big. AND crazy math is needed.